
DeepSeek’s V3.2, Mistral 3 and Kling | Weekly Digest
PLUS HOT AI Tools & Tutorials

Hey! Welcome to the latest Creators’ AI Edition.
The AI model race hit a new gear this week with DeepSeek’s V3.2 release. Meanwhile, Europe joined the party as France’s Mistral launched Large 3, video generation reached new heights with Kling and Runway, and NVIDIA took on autonomous driving.
But let’s get everything in order.
Featured Materials 🎟️
News of the week 🌍
Useful tools ⚒️
Weekly Guides 📕
AI Meme of the Week 🤡
AI Tweet of the Week 🐦
(Bonus) Materials 🎁
Vibe Coding Academy

Vibe Coding Academy teaches Product Managers, Designers, and Software Engineers to build with AI - no traditional coding required.
Whether you want to ship your MVP without a CTO or become the Product Builder who ships features without waiting on dev cycles, mastering AI-powered coding opens new career doors.
With new lessons every week, you’ll stay ahead of the tools - not buried by them.
Featured Materials 🎟️
DeepSeek 3.2 Enters The Game
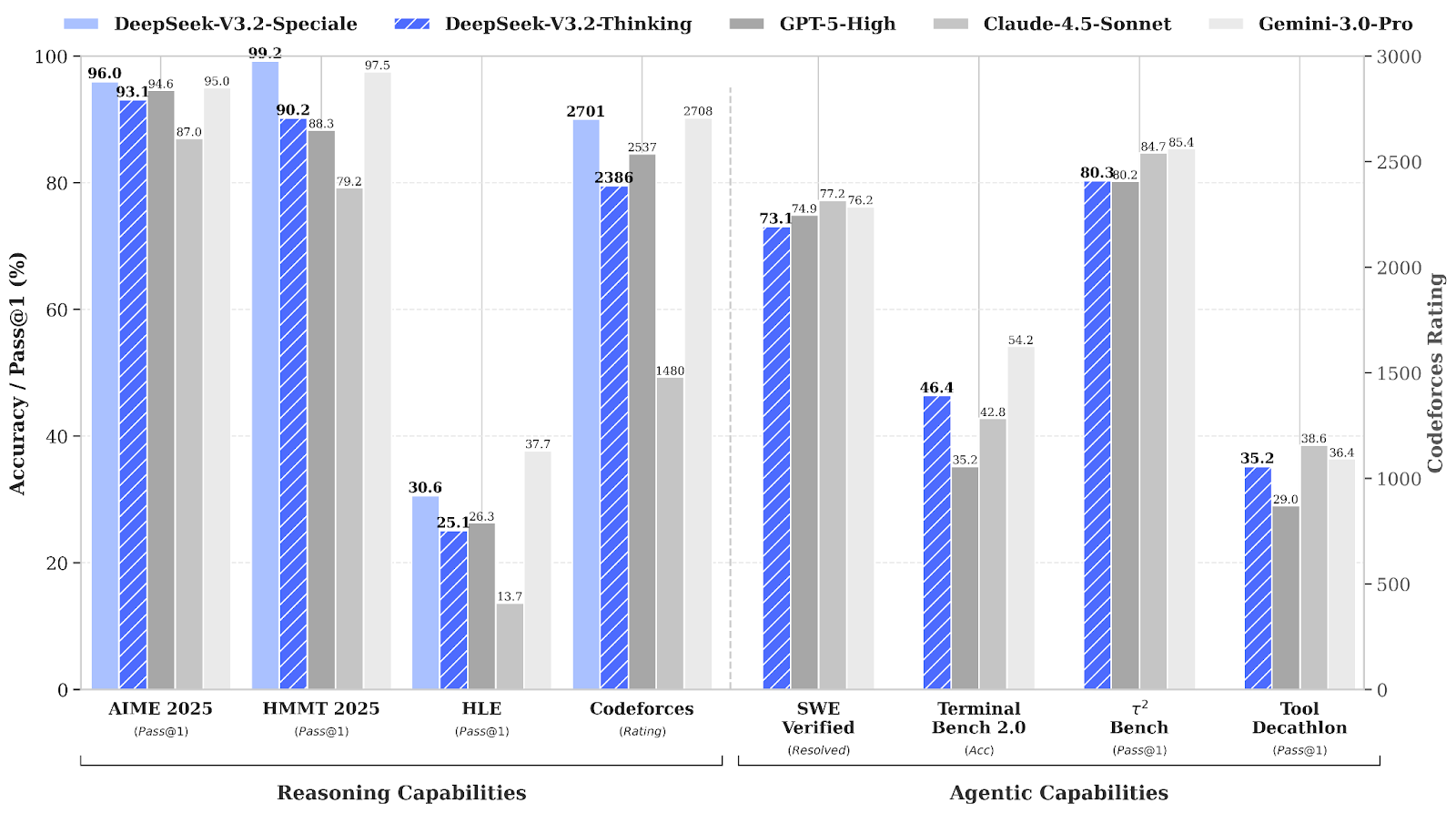
The parade of new models continues.
Though it feels more like a fierce standoff with polite smiles.
And once again, China steps in to break the US-only duel.
DeepSeek has dropped two models: DeepSeek-V3.2 and DeepSeek-V3.2-Special.
The standard Thinking version aims for a balance of quality and cost. It saves tokens but still delivers strong reasoning, especially in agentic tasks.
Speciale is the experimental and no-limits variant. It tops scientific and coding benchmarks and even picked up “gold medals” in international math and informatics competitions.
Key features:
A new sparse-attention system (DSA) that consumes fewer tokens while keeping accuracy. The principle, as in all new models, is the same: the model deliberately chooses only relevant tokens to tackle tasks. Actually, this is the thing that makes the model cheaper and faster without losing reasoning depth, and also lets it handle long context.
Take a look: V3.2 is priced at $0.28 input and $0.42 output per million tokens, undercutting Gemini 3 Pro ($2.00 / $12), GPT-5.1 ($1.25 / $10), and Sonnet 4.5 ($3 / $15)
The devs are pushing aggressive post-training. DeepSeek ran RL at a scale usually seen only in closed labs. First, they train models for math, code, logic, and agent tasks. Each gets a heavy RL. Next, they distill these models into a single unified model. Finally, that unified model goes through a final RL stage.
DeepSeek built a huge synthetic task ecosystem. It includes more than 1,800 environments and over 85,000 complex multi-step prompts that mix tool-use, coding, search, and general reasoning. The point is to stress-test the model on long, structured tasks that feel closer to real agent work instead of short, isolated questions.
Which model will we observe next week, huh?
A quick side note: have you heard that Sam Altman announced an internal “code red” and made the entire team focusing on improving ChatGPT? They’ve postponed shopping, ad features and the Pulse assistant. The reason is that Gemini 3 is catching up in benchmarks. What a show!
News of the week 🌍
Hello from Europe
Oops, I didn’t wait for another week and came up with a new model just right now, and it’s also not from the USA.
French company Mistral released their new flagship Mistral Large 3. In the LMArena ranking, the model took 6th place among open-weight projects and 2nd place among open non-reasoning models. They say the model sets a new standard for global AI accessibility and unlocks new possibilities for enterprises.
Benchmark-wise, it’s on par with DeepSeek-V3.2 exp. and Kimi-K2. The developers state that the model was trained from scratch on a cluster of 3,000 Nvidia H200 GPUs.
Mistral also released smaller models designed to run on devices like laptops, smartphones, cars, and robots, which can be customized for specific tasks.
The company offers a chatbot called Le Chat in English.
Meet Kling O1
Kling unveiled the “world’s first unified multimodal video large-scale model”, meaning you can mix text+images+video all in a single prompt (though I bet in a few weeks it won’t be the only one doing this).
O1 can now:
Do post-production through chat (instead of manual masks and frame-by-frame work, just ask it to remove or replace objects in the video);
Change lighting, backgrounds, and weather;
Sync everything with camera movement and object motion;
Generate flexible video length (3-10 seconds) in Full HD.
The model gets the context on its own and does pixel-level edits.
Already available on Higgsfield.
New Runway’s Gen-4.5

Just after observing “the world’s first”, we proceed to the “world’s top-rated” video model. Gen-4.5 is here.
They’re saying there’s been significant progress in two areas:
Data efficiency during the pre-training stage.
Advanced post-training techniques.
Also, objects move with realistic weight, momentum, and force, liquids flow with proper dynamics, and surface details render with high precision.
Gen-4.5 can handle a wide range of aesthetics, from photorealistic and cinematic to stylized animation, and keep a coherent visual language throughout.
NVIDIA for Driving

In this case, let’s look at the world’s first open reasoning model for autonomous driving, released by NVIDIA DRIVE — Alpamayo-R1 (AR1).
This industry-scale model:
Integrates chain-of-thought reasoning with route planning to achieve level 4 autonomy;
Breaks down complex road scenarios (pedestrian intersections, lane closures, obstacles);
Considers all possible trajectories and picks the optimal route, giving autonomous vehicles the “common sense” to drive as humans do.
Level 4 (High Automation) means the vehicle can fully drive itself without human intervention, but only under specific conditions.
R1 is built on the open NVIDIA Cosmos Reason architecture.
Along with AR1, NVIDIA dropped an ecosystem of Physical AI tools: Cosmos Cookbook (complete developer guide), LidarGen (first world model for generating lidar data), Cosmos Policy (framework for turning video models into robot policies), and ProtoMotions3 (GPU-accelerated framework for training humanoid robots).
A Сircle of Investments
Nvidia also poured $2 billion into Synopsys, a company that makes chip design software, as part of a multi-year partnership between the two. Basically, Synopsys will get to use Nvidia’s tech to make its own software development more efficient, while also getting broader access to Nvidia’s cloud services.
It’s a win-win setup where Nvidia invests in a key player in the chip design ecosystem, and Synopsys gets the tools and computing power to level up its offerings. This deal ranks as one of the bigger AI-related investments of 2025, though it’s still relatively modest compared to some of the mega-deals we’ve seen, like OpenAI’s $300 billion Oracle contract or the massive Stargate project.
Useful tools ⚒️
CyberCut AI - AI video studio for viral social clips
Crow - Make your product AI-native via AI Copilot
Kodey.ai - Build real AI agents that work - not just chat
Contenov - AI tool turning any topic into an SEO blog brief in minutes
Symvol.io - Turn complex text into easy-to-follow explainer videos
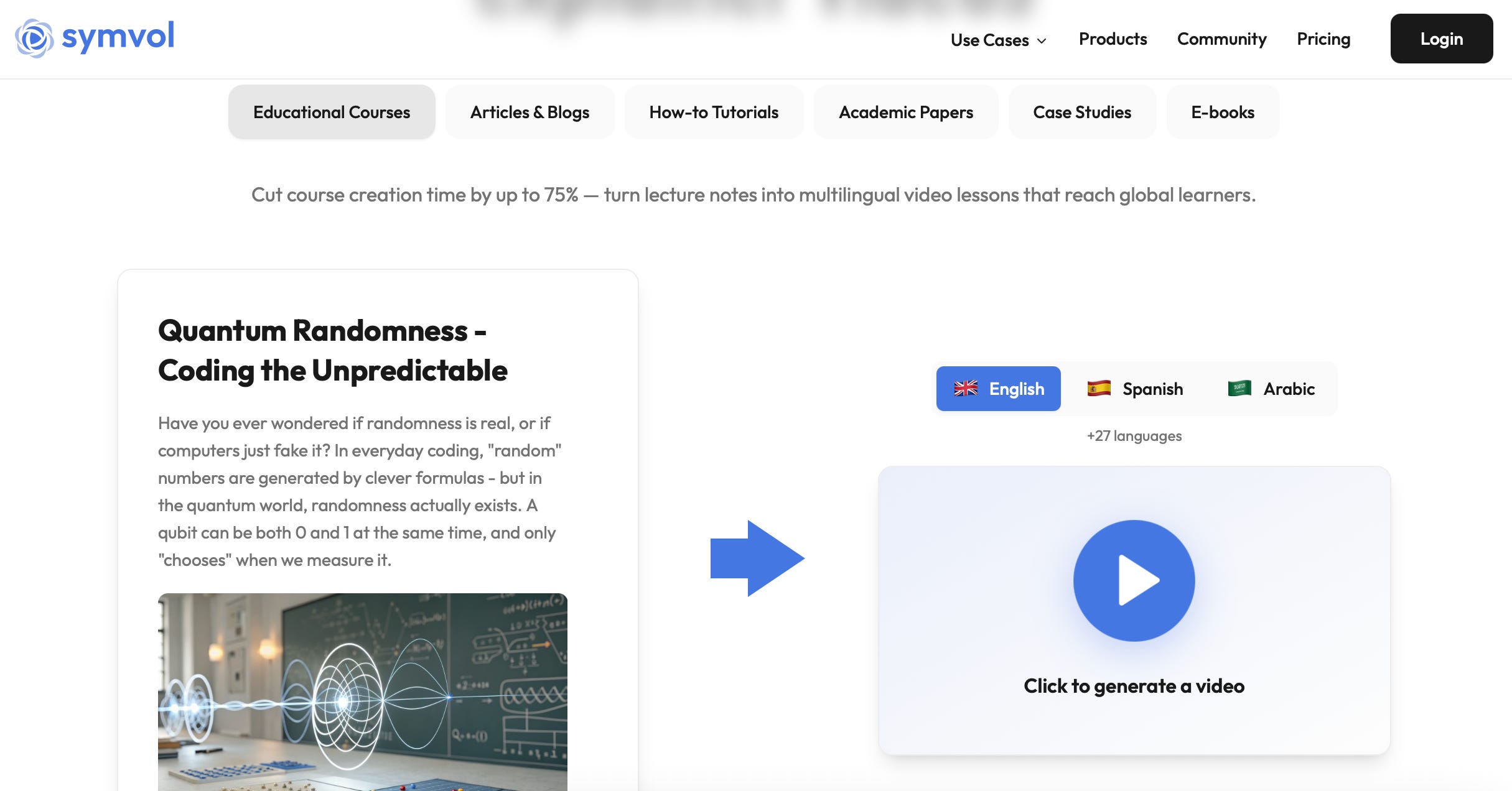
It is an AI platform that transforms any text (articles, guides, e-books, whatever) into educational videos automatically. It handles visuals, animations, structure, and voiceover, supports 30+ languages and 100+ voices, and offers API/enterprise versions for schools and businesses.
Just check out the cool video it created to summarize one of our Digests — Click
Weekly Guides 📕

Create Cinematic AI Ads With Nano Banana Pro + Kling AI - Full Guide
LangSmith Agent Builder Tutorial (No-Code): Build an Email Triage Assistant
Google Opal Tutorial: A Complete Beginner’s Guide to No-Code AI App Development
I Built My Entire Design System in 4 Hours With AI. Full Tutorial (Claude + Cursor + Figma)
AI Meme of the Week 🤡

AI Tweet of the Week 🐦
Bonus Materials 🎁
Is Vibe Coding Safe? Benchmarking Vulnerability of Agent-Generated Code in Real-World Tasks - To learn about dangers around the corner
Look who’s podcasting - To have fun with AI characters that went viral on social media
Artificial Intelligence and the Psychology of Human Connection - To read about the Machine-Integrated Relational Adaptation (MIRA) model that provides a foundational account of when, how, and why AI functions as a relational entity in human ecosystems.
Can AI Really Automate 57 Percent of Work? - To listen
Runway’s new model seems to be crazy good.
But also, DeepSeek is pricing their model like that? How many times is their model cheaper than Gemini or Sonnet? Crazy!