
Autoresearch: The Loop That Improves Your Work While You Sleep
How Karpathy's Experiment Escaped the Lab and Became a Business Tool

When Andrej Karpathy — one of the original architects of modern AI — published this idea in a 630-line open-source script, it got 8.6 million views in two days and hit 26,000 GitHub stars in under a week. Today the repo sits at over 42,000 stars and 5,500 forks, with the community already shipping ports for Windows, Apple Silicon, and non-ML business workflows. The reaction wasn't hype about a new model. It was recognition of a new method.
Karpathy left an agent running on his codebase for two days.
700 experiments. No human in the loop. Every bad idea rolled back automatically. Every winner kept.
The result: an 11% performance gain on a benchmark that thousands of ML engineers compete on.
That’s Autoresearch. And the reason it matters isn’t the ML benchmark. It’s the underlying logic — a loop that can be pointed at almost any measurable problem. Cold email reply rates. Page render speed. Landing page conversions. Retrieval accuracy. Anything with a scoreboard.
Let’s break it down.
The Story Behind the Loop
Karpathy built a system called nanochat — a minimal character-level language model — and gave an agent one job: make it train faster. Not by rewriting everything. By doing one thing at a time.
The agent could touch one file. It could run one experiment. It read one metric. And it had a simple rule: if the number got better, keep the change. If not, revert it. Start again.

After two days and roughly 700 experiments, about 20 changes survived. The benchmark moved from 2.02 hours to 1.80 hours — roughly 13 minutes faster per full training run.
That doesn’t sound dramatic. But think about what actually happened.
No human reviewed 700 experiment results. No one debated which change to try next. No one rolled anything back manually. The loop did all of it — and stacked 20 real improvements cleanly, without one cancelling out another.
That’s the compounding part. And it’s what makes this different from just asking an AI to “help improve” something.
How Autoresearch Actually Works
It’s easier to understand as a loop than as a codebase.
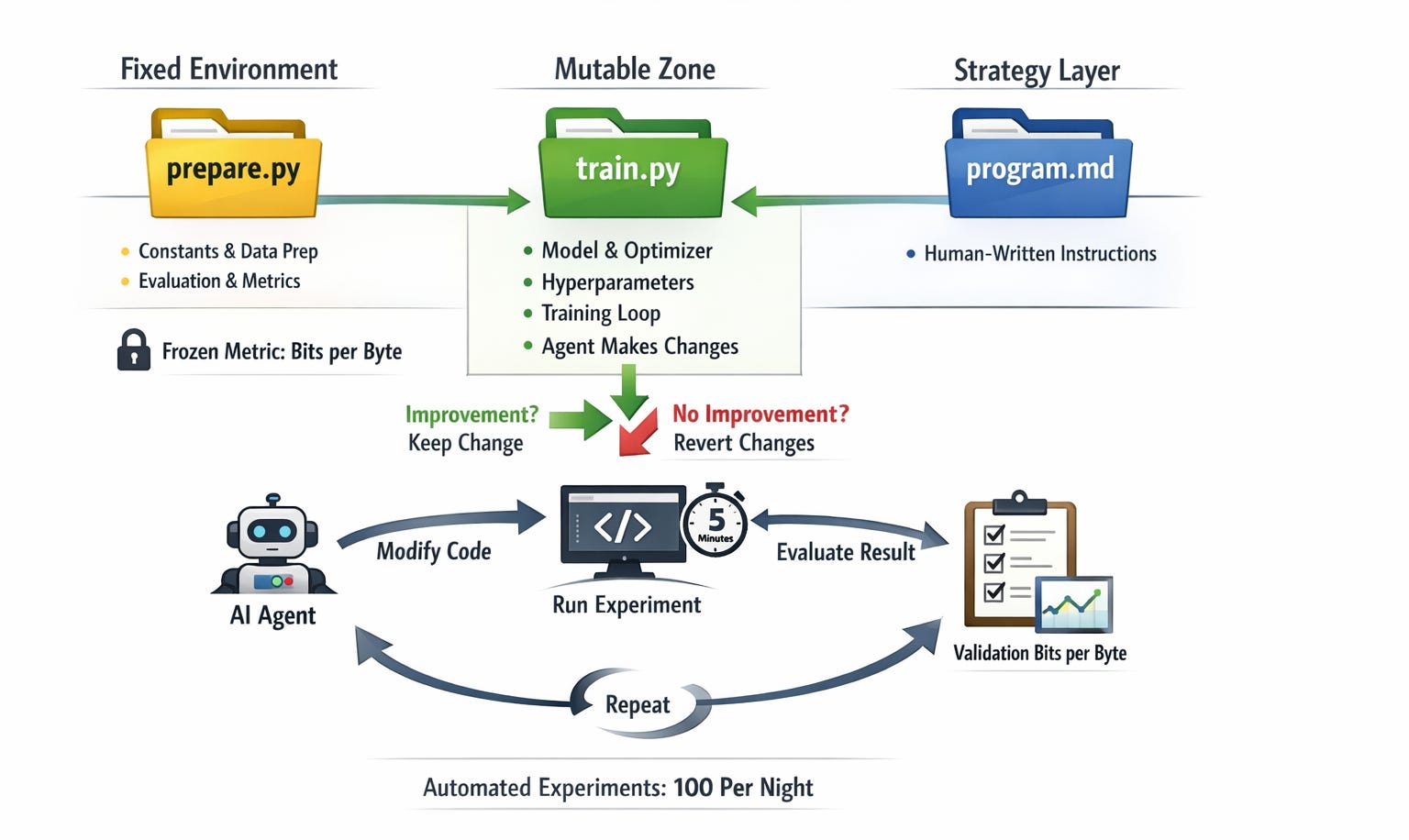
Here’s how the loop works in plain language, step by step:
1. You write the goal in plain English. You create a simple text document and write your instructions: what you want the AI to improve, what it’s allowed to touch, and what “better” looks like. That’s the only thing you write. The AI does everything else.
2. The AI makes one small change. It opens the one file it’s allowed to edit and tries something — maybe it adjusts how fast the model learns, maybe it changes how information is grouped and processed. One small change. Nothing else.
3. It runs a 5-minute test. Every single experiment runs for exactly 5 minutes — no exceptions. The fixed time is what makes experiments fair. Every change gets the same amount of time to prove itself, whether it’s a tiny tweak or a bigger structural change.
4. It checks one number. At the end of the 5 minutes, the system produces a single score. Lower is better. The AI asks one question: is this score lower than before the change?
5. Keep or undo — automatically. If the score improved, the change is saved and becomes the new starting point. If the score got worse or stayed the same, the change is completely undone — as if it never happened. No human needs to review anything. It happens automatically.
6. Repeat, immediately. The AI doesn’t pause or wait for approval. It goes straight back to step 2 and tries something new, building on whatever worked and ignoring whatever didn’t. This happens around 8 to 12 times every hour.
7. You check the results in the morning. Every improvement that survived is recorded. Every failed attempt was automatically cleaned up. You wake up to a clear history of what was tried, what worked, and by how much — often 60 to 100 completed experiments from a single overnight run.
The core idea is simple: try something → measure it → keep it or undo it → repeat. What makes it powerful is that a machine can run this loop dozens of times while you sleep, without getting tired, distracted, or tempted to keep a bad idea just because it took effort to come up with.
The interesting thing is that this loop works in the same way across wildly different domains. Which is exactly what the next three cases show.
Now lets check some cases
Case 1: Andrej Karpathy + nanochat — Where the Pattern Came From
The original implementation is still the clearest.


Result: 700 experiments over two days. 20 surviving changes. “Time to GPT-2” benchmark went from 2.02 hours → 1.80 hours. An 11% improvement on a leaderboard thousands of engineers compete on.
How it worked: Think of the agent as a junior researcher with a key to one locked room. It could edit the mutable training layer, run the same 5-minute experiment each time, and read the same frozen metric. Because every run used the same budget, the winning changes stacked cleanly instead of creating noise.
What it means for you: If you have any process that takes 1–2 hours per full run and repeats regularly — training pipelines, content workflows, benchmark suites — an 11% improvement compounds fast. Across 50 runs per month, that’s roughly 11 hours back. And you didn’t have to review a single experiment.
The real takeaway isn’t the benchmark. It’s this: once you have a clean loop with a frozen metric, the system starts doing research on your behalf.
This connects directly to something we covered in depth in our post on context engineering — the main control surface in agent workflows often sits in how you structure the instructions and context itself. Autoresearch is the same idea applied to iteration.
