
Kimi K2: The Open Model Getting Momentum
Here's all you need to know


Hey!
You couldn't have not heard about about Kimi K2 last week because it gained Momentum across X, LinkedIn and Substack.
Kimi K2 from Moonshot AI is interesting because of MoE approach. It’s a Mixture-of-Experts model that activates only what it needs, which makes it efficient and scalable.
In this post, we’ll cover:
How K2 breaks down complex tasks and chooses the right skills to solve them
How it reads long documents without losing track
How it learns to use tools like a real assistant
What its benchmark numbers actually mean
And some cool examples you can try yourself 🔥
If you’re here to actually understand how K2 works, you’re in the right place. Let’s break it down.
What Is Kimi K2? A Quick Overview
K2 is a large language model built by Moonshot AI, an AI company based in China, designed not just to understand language but to act on it. K2 combines language understanding with real action and delivers power and flexibility that stand out from the usual text generators.
Here’s what makes it different:
It uses a “Mixture of Experts” architecture. That means it’s huge, over a trillion parameters but only activates parts of the network when it needs to, so it stays efficient.
It can keep track of super long conversations or documents, handling up to 128,000 tokens at once. (not bad for Open Sourced MoE model)
K2 is trained to do more than chat. It can call external tools, run code, browse the web, and chain these actions together without constant handholding.
You can run it locally if you have the hardware, or access it through an API or just use the Web version
Now, let’s dig into how it’s designed and trained to make all this possible.
Architecture and Training Details
Scaling a language model to a trillion parameters isn’t a matter of just throwing more GPUs at the problem. The considerable size brings big challenges: compute costs go up fast, memory fills, and training gets unstable quickly. Kimi K2 solves this with a clever architectural twist known as Mixture-of-Experts (MoE), which means that instead of using all of its parameters for every input, it selectively activates parts of the model. This approach allows K2 to scale up without requiring excessive amounts of computation or memory.
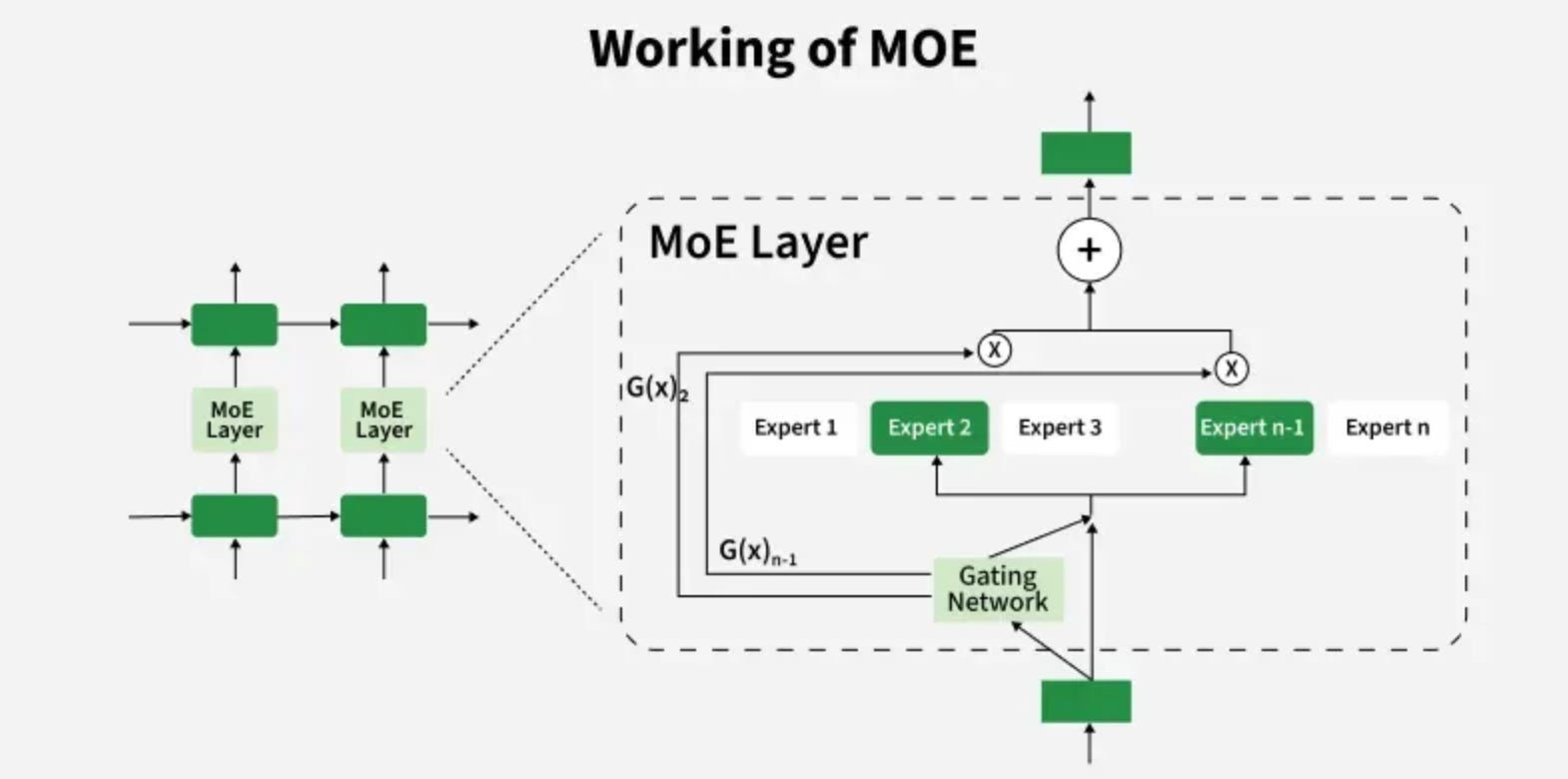
If you want to know more about the architecture of MOE, read this article.
At a high level, K2’s model is made up of 384 smaller subnetworks called experts. Each expert is a specialist trained to focus on certain types of patterns or features in the data. When the model processes a word or token, it doesn’t send that token to all 384 experts. Instead, it uses a gating network to decide which experts should be involved in processing that token.
This process of deciding which experts handle each token is known as routing. The gating network assigns scores to each expert for a given token, reflecting how relevant each expert is. Then, only the top 8 experts with the highest scores are selected to process that token. This selective routing is crucial because it allows the model to use about 32 billion parameters per token instead of all trillion which makes inference and training much more efficient.
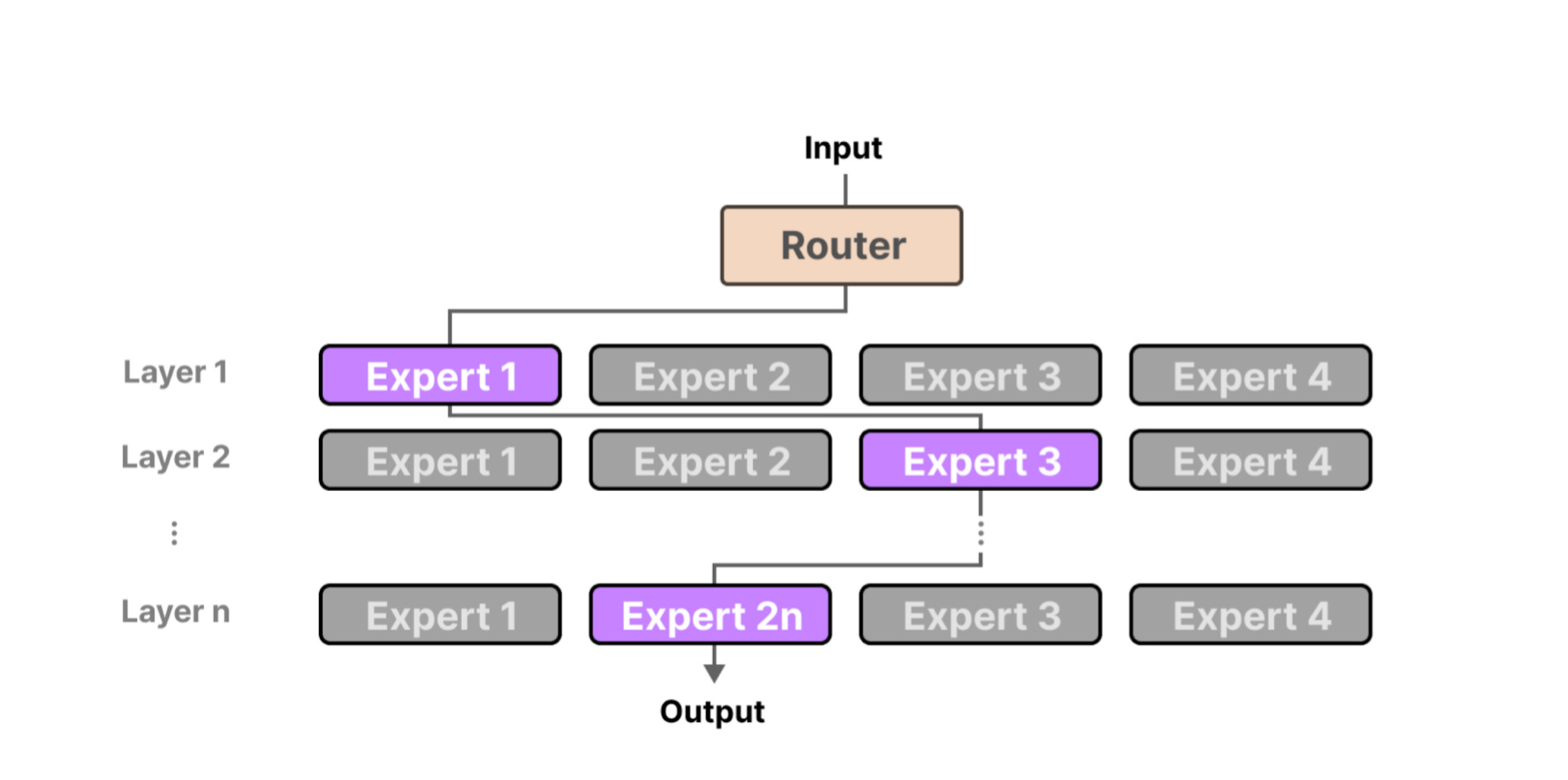
Why 8 experts? It’s a balancing act. More experts per token means richer understanding but heavier compute. Fewer experts risk losing nuance. Eight experts hit the sweet spot for K2, balancing specialization with efficiency.
Training a model like K2 is not straightforward. The gating network’s output consists of raw values called logits. These logits determine how strongly each expert is selected. Without careful control, these logits can grow uncontrollably large during training, leading to unstable updates and poor model performance.
Moonshot’s answer? MuonClip, a stabilization technique that clips gating logits within a safe range during training. It might sound simple, but it’s crucial. By clipping the logits within a stable range, MuonClip prevents training from becoming unstable, allowing K2 to learn effectively over massive datasets.
One of K2’s most impressive features is its ability to process extremely long sequences of text. Achieving this requires smart memory management and optimized attention mechanisms.
Instead of attending to every token pair (which would be computationally insane), K2 uses sparse attention mechanisms that focus only on the most relevant tokens when processing the input which significantly reduces the required compute. Additionally, it employs specialized positional embeddings to keep track of token positions accurately across the very long input. Efficient memory management techniques ensure that K2 can maintain and retrieve the necessary information during inference without running out of resources.
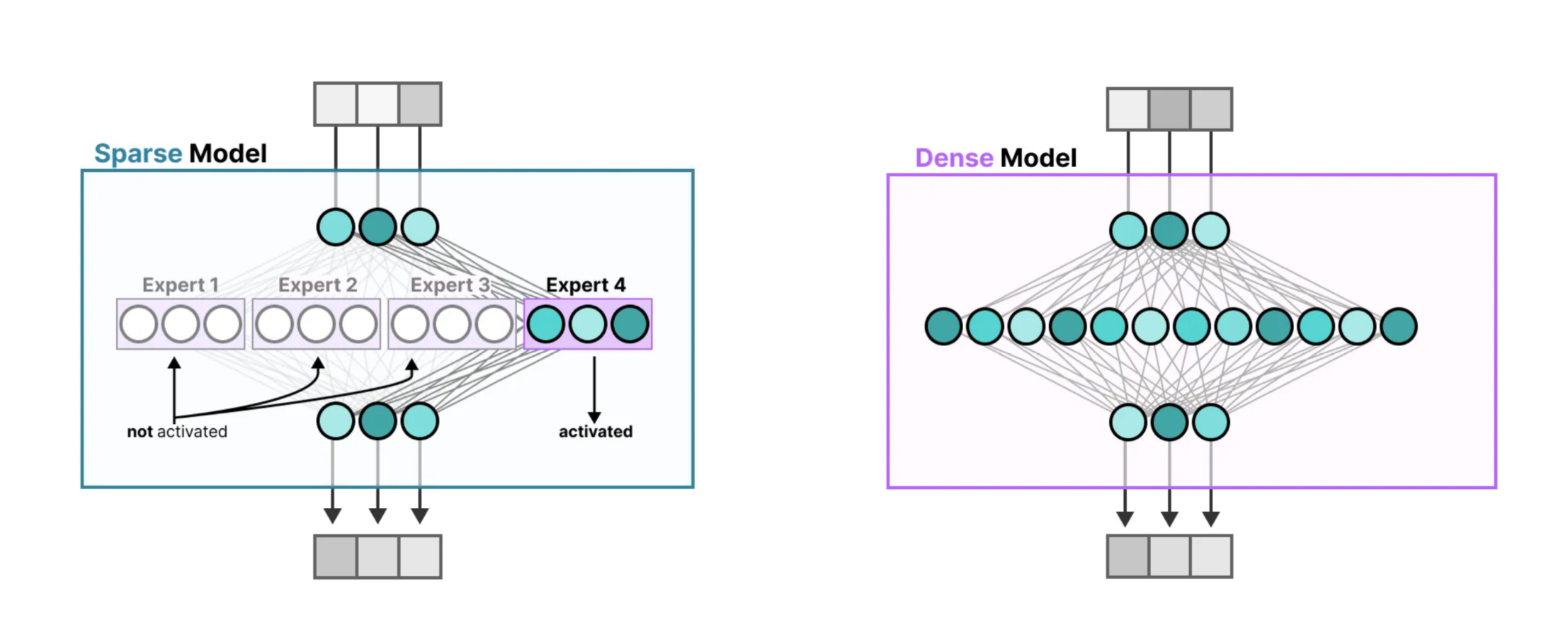
These images show a clear comparison between Spare and Dense Models. In dense models, all parts of the network are active for every input which makes them powerful but inefficient. In sparse models , only a few specialized “experts” are activated based on the input, which reduces computation and scales better. Instead of firing up the entire model, it picks just the right parts for the job, like calling in specialists instead of the whole team.
All these pieces, MoE routing, MuonClip stabilization, and efficient long-context attention, come together to create a model that’s not just huge, but practical and powerful.
Performance and Benchmarks
Let’s talk about results. If Kimi K2 wants to compete with models like GPT-4, Claude, or Gemini, its benchmarks have to hold up. And they do.
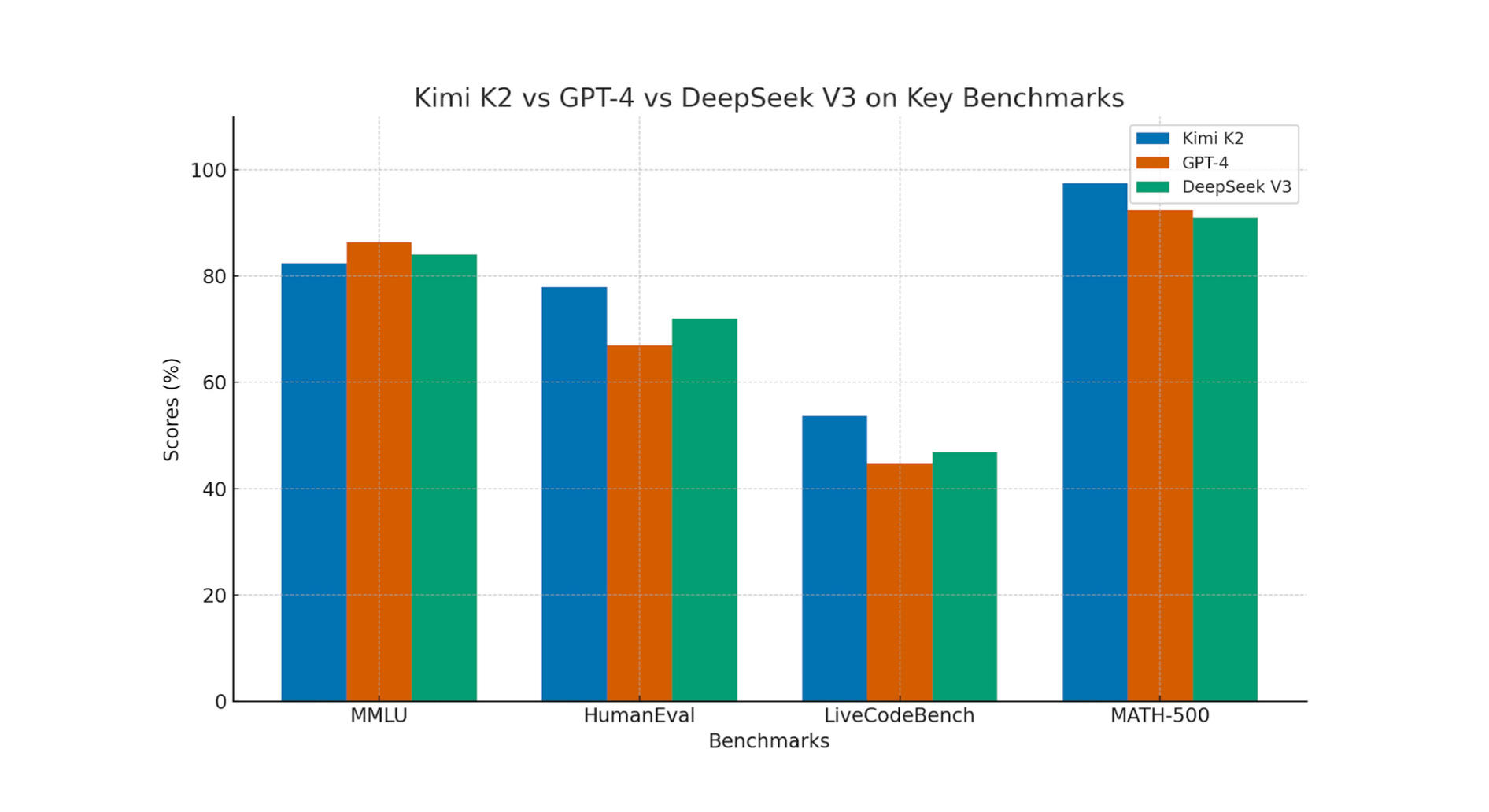
On MMLU, K2 scores 82.4%, placing it right next to GPT-4 and Claude 3.5. That’s a broad academic test spanning history, math, law, and more. Hitting above 80% means the model isn’t just parroting facts, it’s demonstrating reasoning skills on par with leading models.
On HumanEval, K2 reaches 77.9%, which reflects its ability to generate Python code that actually runs and solves problems. GPT-4 is only slightly ahead here. For people building dev tools or AI coding assistants, this is a big deal.
Then there’s LiveCodeBench, which evaluates real-world coding tasks instead of contrived examples. K2 scores 53.7%, ahead of GPT-4.1 (44.7%) and DeepSeek V3 (46.9%). It shows the model can tackle engineering-level challenges, not just toy problems.
Here’s everything you need to know about DeepSeek!
On MATH-500, a high-difficulty symbolic math test, K2 reaches 97.4%. That puts it ahead of GPT-4 (92.4%) and Claude 2.1 (88.0%), showing serious reasoning ability in structured, complex domains.
Don’t forget to share this post with your friends who are into AI!
Getting Started with K2
In this section, we’ll walk through setting up K2, whether you want to run it locally or connect through Moonshot’s API.
